18.语音模型之语音识别
18.语音模型之语音识别
现在的大模型应用中,语音输入是一个非常常见的场景,因此语音识别就是一个很基础的要求了;当然在没有大模型的时代,语音识别也不算少见,接下来我们看一下,如何使用SpringAI来实现语音识别
下面的演示,我们将基于 硅基流动 的免费语音识别模型来完成
一、实例演示
首先我们需要创建一个SpringAI的项目,基本流程同 创建一个SpringAI-Demo工程
1. 初始化
我们借助OpenAI的接口风格来完成语音识别接入,因此需要引入对应的依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>
在配置文件中,配置模型相关的配置, 对应的 application.yml 内容如下
spring:
ai:
openai:
# api-key 使用你自己申请的进行替换;如果为了安全考虑,可以通过启动参数进行设置
api-key: ${silicon-api-key}
transcription:
api-key: ${silicon-api-key}
base-url: https://api.siliconflow.cn/v1
transcription-path: /audio/transcriptions
options:
model: FunAudioLLM/SenseVoiceSmall
response-format: text
chat: # 聊天模型
options:
model: deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
base-url: https://api.siliconflow.cn
# 修改日志级别
logging:
level:
org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor: debug
然后在资源目录(resources)下,准备一个用于测试的音频文件 test.mp3
2. 测试端点
然后创建一个 Controller 用于测试,这里直接使用注入的 TranscriptionModel 来进行语音模型的交互
@RestController
public class AudioTransactionController {
private Logger log = org.slf4j.LoggerFactory.getLogger(AudioTransactionController.class);
/**
* 直接使用默认注册的模型对象来进行交互
*/
@Autowired
private TranscriptionModel initTranscriptionModel;
@Value("classpath:/test.mp3")
private Resource resource;
}
3. 获取语音识别内容
接下来我们直接使用transcriptionModel来进行大模型的交互,看看语音识别效果
/**
* 使用OpenAI风格的语言识别
*
* @return
* @throws IOException
*/
@GetMapping(path = "translateAudio")
@ResponseBody
public Object translateAudio() throws IOException {
AudioTranscriptionOptions options = OpenAiAudioTranscriptionOptions.builder()
.model("TeleAI/TeleSpeechASR")
.responseFormat(OpenAiAudioApi.TranscriptResponseFormat.TEXT)
.build();
AudioTranscriptionPrompt prompt = new AudioTranscriptionPrompt(resource, options);
AudioTranscriptionResponse response = initTranscriptionModel.call(prompt);
log.info("response -> {}", response);
return response.getResult().getOutput();
}
整体的使用方式和文本模型大差不差,使用 音频文件 + AudioTranscriptionOptions 来构建提示词 AudioTranscriptionPrompt,然后直接通过 model.call() 进行大模型调用,获取返回结果
对于 AudioTranscriptionOptions 可以设置语音、温度、模型、返回格式等各种参数(当然不同的模型厂家支持情况并不一样)
接下来我们直接访问这个端点,看下识别情况
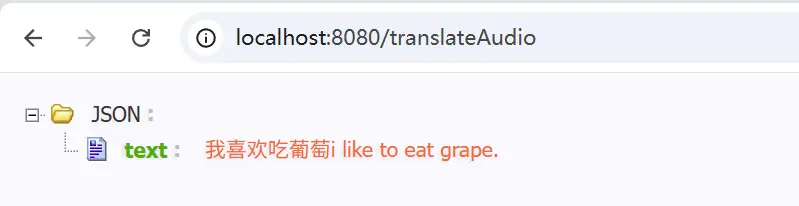
可以看到中英文的音频都被正确的识别出来了
4. 手动初始化Model
前面使用到的是OpenAI starter自动注入的TranscriptionModel,当然我们也可以通过OpenAiAudioApi来手动实现一个TranscriptionModel
接下来看看具体的实现方式
public AudioTransactionController(Environment environment) {
OpenAiAudioApi openAiAudioApi = OpenAiAudioApi.builder()
.apiKey(getApiKey(environment, "silicon-api-key"))
.baseUrl("https://api.siliconflow.cn")
.build();
transcriptionModel = new OpenAiAudioTranscriptionModel(openAiAudioApi,
OpenAiAudioTranscriptionOptions.builder().model("TeleAI/TeleSpeechASR").build());
}
private String getApiKey(Environment environment, String key) {
// 1. 通过 --silicon-api-key 启动命令传参
String val = environment.getProperty(key);
if (StringUtils.isBlank(val)) {
// 2. 通过jvm传参 -Dsilicon-api-key=
val = System.getProperty(key);
if (val == null) {
// 3. 通过环境变量传参
val = System.getenv(key);
}
}
return val;
}
看了上面基于 OpenAiAudioApi 创建 TranscriptionModel 的方式,我们会惊奇的发现,这种实现和前面介绍的OpenAI风格的创建对话模型的方式简直是雷同了(这样挺好的,减少了我们的学习成本😊)
接下来写个demo验证下效果如何(具体的使用方式和前面并没有区别)
@GetMapping(path = "translateAudioV2")
@ResponseBody
public Object translateAudioV2() throws IOException {
AudioTranscriptionOptions options = OpenAiAudioTranscriptionOptions.builder()
.responseFormat(OpenAiAudioApi.TranscriptResponseFormat.JSON)
.model("FunAudioLLM/SenseVoiceSmall")
.language("zh")
.build();
AudioTranscriptionPrompt prompt = new AudioTranscriptionPrompt(resource, options);
AudioTranscriptionResponse response = transcriptionModel.call(prompt);
log.info("response -> {}", response.getResult());
return response.getResult().getOutput();
}
5. 踩坑记录
整体的音频模型的使用方式比较简单,但是我在实际使用的时候发现了几个蛋疼的问题
现在的 1.1.2 版本中,只支持配置 base-url,对应的语音是被的path路径在代码中写死的为/v1/audio/translations
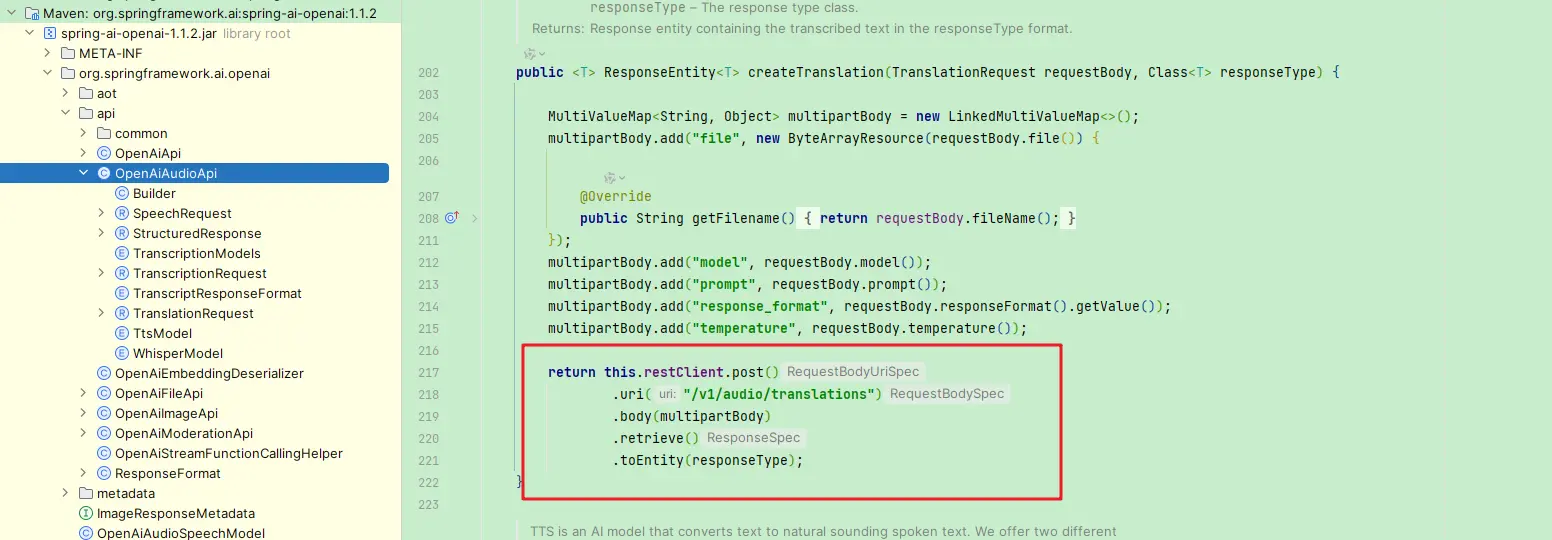
注:即便你的大模型支持openStyle的接口风格,但是若path路径不一致,那也是无法使用 openai-starter 的
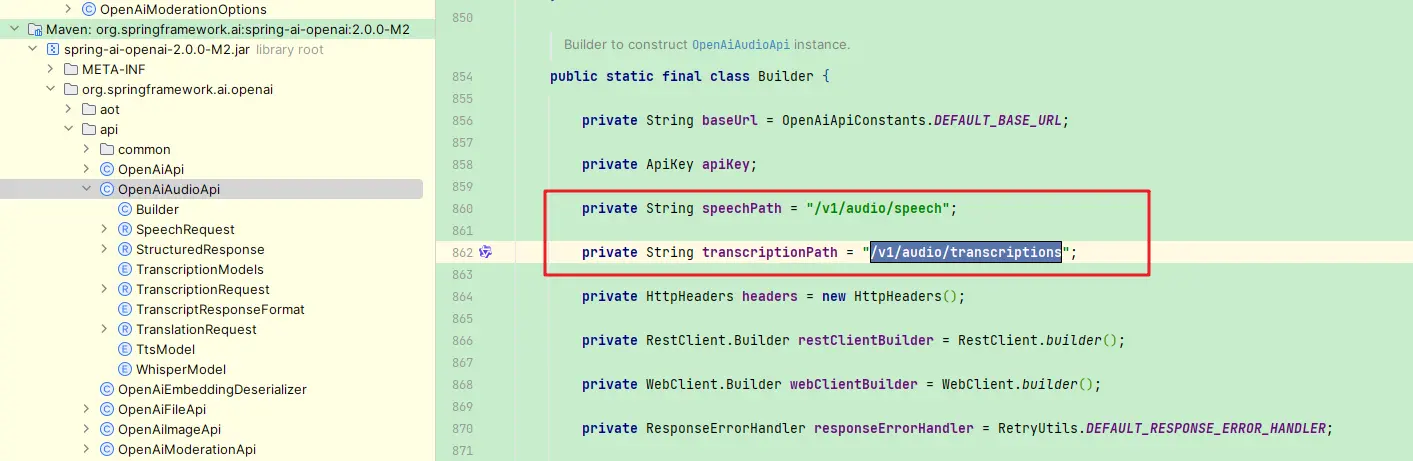
这个问题在
SpringAI ~ 2.0.0-M2得到了解决,如下图
第二个踩坑点就是使用OpenAI的start进行语音识别时,大模型的服务端一直返回异常 {"detail":[{"type":"missing","loc":["body","file"],"msg":"Field required","input":null}]}

音频文件明明上传了,为什么模型端提示没有呢?
主要的原因是默认的 RestClient 其底层 Client 不是 JDK HttpClient,而是某个不支持 multipart 的实现,从而到这了这个问题,对应的解决方式就是强制指定
RestClient restClient = RestClient.builder()
.requestFactory(new JdkClientHttpRequestFactory())
.build();
所以你会在项目源码的 Application 中看到 RestClient.Builder 的注册,就是为了解决上面这个问题而出现的
@SpringBootApplication
public class S19Application {
public static void main(String[] args) {
SpringApplication.run(S19Application.class, args);
System.out.println("启动成功,前端测试访问地址: http://localhost:8080/translateAudio");
}
@Bean
public RestClient.Builder restClientBuilder() {
return RestClient.builder()
// 若底层 Client 不是 JDK HttpClient,而是某个不支持 multipart 的实现,从而导致音频上传无法被正确解析,此时可以通过下面这一行来调整底层的 Client
.requestFactory(new JdkClientHttpRequestFactory())
.messageConverters(converters -> {
converters.add(new FormHttpMessageConverter());
converters.add(new ResourceHttpMessageConverter());
converters.add(new StringHttpMessageConverter());
});
}
}
二、小结
本文介绍了语音大模型的使用方式,目前spring-ai官方也只针对OpenAI进行的支撑,不同的厂商的语音模型可能会有自己的特定交互方式,大家在使用的时候需要注意甄别
本文对应的项目源码为: S19-audio-transaction